6.s081 - Lab01 - Xv6 and Unix utilities
lab01的学习记录和题解
About
该课程前几章最好连续着看,如果中间搁置一段时间再看容易串不起来,主播现在就是重新看一遍(事实证明后面看了再来看一遍确实常看常新)
本课程的大多数内容和实验都是基于一个xv6操作系统的扩展实现的,我们将手动完善这个系统,这是一个Unix的简化系统,它将在qemu模拟器上模拟出来,在这里我想先解释一下qemu和xv6的启动是怎么个事,虽然这是lab02才会学习的内容
QEMU: 全称quick emulator,当脑中想到这个东西的时候,与其将其想象为一个C语言程序,你更应该将其想象为一个主板,而QEMU在真正的硬件上运行使得不同架构的系统可以运行在你的计算机上
介绍操作系统的组成结构就不得不提底层的硬件,常见的硬件资源包括CPU,内存,磁盘,网卡这些,而在操作系统的最上层,我们会运行各种程序如文本编辑器(VI),C编译器(CC),Shell等,这些运行的程序都在同一个空间中,我们称之为用户空间(Userspace),而与用户空间所对应区别于的,有一个程序会始终运行即Kernel,它里面包含各种服务来维护用户空间的进程,而本课程的关注点也主要在于Kernel,连接Kernel和用户空间的接口和Kernel内软件的架构等。
Kernel中的服务最为值得关心的其中一个是文件系统,而另一个即是进程管理系统,对于前者,我们可以认为其存在的作用是管理文件内容并找出文件具体在磁盘的位置,后者中,每一个用户空间程序都被称之为一个进程,有自己的内存和共享的CPU时间,Kernel会管理内存的分配问题,对内存进行复用和划分。
接下来我们同时对应用程序如何和Kernel交互以及他们之间的接口长什么样感兴趣,这种接口一般通过系统调用(System Call)来完成,系统调用会实际上运行在内核空间。给个例子,如果一个应用程序想要打开一个文件,那么会调用open这个系统调用,并将文件名作为参数传入
关于系统调用,在xv6中,它们都是实现在kernel中的sysfile.c中的,如open调用在其中实现为sys_open,这些定义在kernel中因而往往有对硬件直接的操控权限,但user层中往往需要调用这些系统调用,所以我们在user中有usys.pl这样的一个脚本,在编译整个系统后,会根据脚本内容生成对应的文件,而汇编文件usys.S就是这样生成的,有了它我们就可以在user层中调用这些系统调用
管道(pipe)
管道是内核的一种缓冲区,有读写两端,其实现实际上是在内核内存中,这也解释了为什么它能有跨进程读写的基础,而管道正式为了进程间的交互实现的,以文件描述符对的形式作用,语法上创建管道为pipe(p),其中p为一个数组,当创建管道后会和文件描述符一样分别将当下最小的两个文件描述符分配给p[0]和p[1]。需要注意的是管道的两端有明确的读写端区分,即数据流向是单向的,只能由p[1]写入并由p[0]流出被读取
通过一个实例来讲解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p);
if(fork() == 0) {
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
exec("/bin/wc", argv);
} else {
write(p[1], "hello world\n", 12);
close(p[0]);
close(p[1]);
}
这里在创建了管道后将读写描述符记录在数组p中,而在创建了子进程后,在子进程中关闭描述符0再调用dup函数,将管道的读端口拷贝到描述符0上,这个时候读端口对应了两个描述符,若想理解这个过程可以看作管道的两个端口也是一种文件的抽象,这就像Unix的设计理念一切皆文件一样,调用dup的过程实际上是找到p[0]对应的文件表项并创建新的文件描述符指向这个表项,在这里即是0,然后将新描述符返回
而像wc这样的程序,一般都是从描述符0来获得数据,它本身并不关心是从哪来的,而0对应的是标准输入还是管道的读端则是Shell做的事情
文件系统(file system)
让我们简单介绍一下xv6中文件系统实现的大概流程,从一开始的open打开一个文件开始(这里的文件是文件和目录的抽象,两者都可以视作文件,只有硬盘中实际存储内容的不同),其会返回一个值即我们的文件描述符fd,它存储在用户进程的内存空间中,但只是一个索引,在内核空间中有一个结构体为proc,是用来描述一个进程的状态的,其有一个指针数组struct file *ofile[NOFILE],用文件描述符的索引来找到对应的指针,如current_process->ofile[3],它指向同样存储在内核空间中的file结构体,它是文件共享的基础,基多个进程的多个fd都可以指向这个偏向根本性的结构体,它也叫文件打开实例,包含了其所代表文件的状态信息如type文件类型——是普通文件还是设备还是管道、ref引用计数、读写权限、ip——指向内存中inode结构的指针、off文件偏移量还有设备号等。再然后就是通过ip定位到内存中的inode结构,这里存储着文件本身的核心元数据,包括其文件类型、连接数、大小以及最关键的指向文件数据块的信息,之后通过这些信息(此处可以粗略地理解为一组指针)找到真实存储的内容,这些内容对于普通文件来说是一组字节,而对于特殊的目录来说是一个目录条目列表,每个条目包含文件名和文件名对应的inode号,所以也可以往下递归地找到后面的文件和目录,这种结构定义为dirent,所以可以用while(read(fd, &dir, sizeof(dir)) == sizeof(dir))来循环遍历所有的子目录和文件
Xv6 and Unix Utilities
This lab will familiarize you with xv6 and its system calls
键入
make qemu,构建模拟器然后运行xv6,键入Ctrl-a x以退出
Lab1要求我们实现一些应用程序,为了实现这些应用程序我们将调用一些系统调用接口,而这些接口有着真正能调用硬件资源的权限,所以也是我们完成应用程序的基础
sleep
你可能会疑惑为什么系统中有这么一个
sleep接口却还要写这样一个应用程序,那是因为所以系统调用都是用来帮助写应用程序的,而Shell要执行命令需要一个真正的程序作为命令,也就是写的sleep.c文件,这也解释了系统调用接口和用户接口的区别
sleep应用程序实现:
by the way, 在nvim中要想复制到系统剪切板需要键入
" + y,这里的双引号是为了告诉系统调用+寄存器也即系统剪切板寄存器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int args, char *argv[])
{
if (args > 2) {
fprintf(2, "Please enter yout arguments!\n");
exit(1);
} else {
int n = atoi(argv[1]);
sleep(n);
exit(0);
}
}
关于sleep系统调用是如何实现的,以及更底层的系统原语等,还是等后面学到再深究
这里主要思想是处理参数的数量以及将参数字符串转换成整数类型,关键注意点在于最后用的是exit(0)而非return 0,前者是直接退出了这个进程,后者只是返回入口点,也许在xv6中较为精简,没有用于处理返回后退出的exit,所以如果在这些lab中用return 0会直接卡住
pingpong
该程序设计本意是为了让学员了解进程间的交互——管道的使用,要求是父进程向子进程发送一个字节并在子进程接受,在接受之后再向父进程发送一个字节,通过完成程序能够加深对管道的理解
pingpong应用程序实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int args, char *argv[])
{
int p[2];
char buf[2];
char *parmsg = "a";
char *chdmsg = "b";
pipe(p);
if(fork() == 0) {
if(read(p[0], buf, 1) != 1) {
fprintf(2, "Cannot read from parents!\n");
exit(1);
}
printf("child received character : %c\n", buf[0]);
//close(p[0]);
printf("%d: received ping\n", getpid());
if(write(p[1], chdmsg, 1) != 1) {
fprintf(2, "Cannot write to parents!\n");
exit(1);
}
//close(p[1]);
exit(0);
} else {
if(write(p[1], parmsg, 1) != 1) {
fprintf(2, "Cannot write to child!\n");
exit(1);
}
//close(p[1]);
//wait(0);
if(read(p[0], buf, 1) != 1) {
fprintf(2, "Cannot read from child!\n");
exit(1);
}
printf("parents received character : %c\n", buf[0]);
//close(p[0]);
printf("%d: received pong\n", getpid());
exit(0);
}
}
这里用a和b分别代表由父进程和子进程传递给对方的信息,一个字节符合题目要求,而read函数的特性决定了它在对应端口的描述符关闭前会一直等待数据读入,所以不论父子进程的前后运行关系都会在接受到之后再进行下一步的运行
primes
素数筛,每次从管道读端得到的数据选出第一个即最小的一个即为质数,并用它对剩下的质数进行筛选,如果是其倍数则不是质数,将筛完的结果传入下一个管道,依次更新得出所有质数,图解如下:
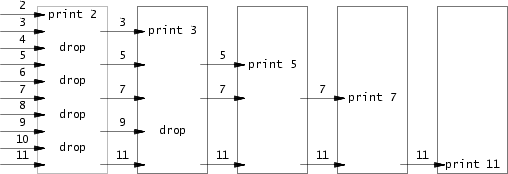
primes应用程序实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
void primes(int *p) {
int a, b;
close(p[1]);
if(read(p[0], (void*)&a, sizeof(a)) != sizeof(a)) {
fprintf(2, "Read fail!\n");
exit(1);
}
printf("prime %d\n", a);
if(read(p[0], (void *)&b, sizeof(b))) {
int p1[2];
pipe(p1);
if(fork() == 0) {
primes(p1);
} else {
close(p1[0]);
do {
if(b % a != 0) {
write(p1[1], (void *)&b, sizeof(b));
}
} while(read(p[0], (void *)&b, sizeof(b)));
close(p[0]);
close(p1[1]);
wait(0);
}
exit(0);
}
}
int main(int argc, char *argv[]) {
int p[2];
int start = 2;
int end = 35;
pipe(p);
//close(p[0]);
for(int i = start; i <= end; i++) {
if(write(p[1], (void *)&i, sizeof(i)) != sizeof(i)) {
fprintf(2, "Write fail!\n");
exit(1);
}
}
close(p[1]);
primes(p);
exit(0);
}
整个筛选过程有两个管道p和p1,对于一个进程而言,分别表示从上一进程传进来的以及要传入到下一进程的,所以主要在于一些细节问题:在C语言中,read一般会读入指定数量的数据,除非识别到对应端口的关闭,所以我们需要在进入下一进程前就把对应的写端给关闭,从而在read循环读入数据时能够在读完最后一个数据后恰好返回0从而退出循环
find
find程序接受两个参数,一个是路径一个是寻找对象的名称,如
find . b就是在当前目录下找b这个文件,哪怕遇到子目录也会递归寻找。这个程序对文件和目录的操作需要进一步的理解,因此我们在前一部分的文件系统板块已经有了相关说明
find应用程序实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void find(char *path, char *filename) {
char buf[512], *p;
int fd; //文件描述符
struct dirent dir; //目录信息
struct stat st; //文件状态
if((fd = open(path, 0)) < 0) {
fprintf(2, "find: cannot open %s\n", path);
return;
}
if(fstat(fd, &st) < 0) {
fprintf(2, "find: cannot stat %s\n", filename);
close(fd);
return;
}
switch(st.type) {
case T_FILE: //讨论给定路径是文件的情况
//返回最后一个'/'的位置,因为这些系统调用有些和C语言标准库冲突,故不能用标准库的一些简便函数
char *name;
for(name = path + strlen(path); name >= path && *name != '/'; name--) ;
name++;
//操作之后name刚好指向需要对比名字的那个字符串的第一位上
if(strcmp(name, filename) == 0) {
printf("%s\n", path);
}
break;
case T_DIR: //讨论给定路径是目录的情况
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof(buf)) {
printf("find: path too long\n");
break;
}
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while(read(fd, &dir, sizeof(dir)) == sizeof(dir)) {
if(dir.inum == 0 || (strcmp(dir.name, ".") == 0) || (strcmp(dir.name, "..") == 0)) //只有'.'目录和'..'目录都跳过才能正确,而在一个目录中,通常这两个是排在最前面的两个结构
continue;
memmove(p, dir.name, DIRSIZ);
p[DIRSIZ] = 0; //理解为 = '\0',二者是等价的
if(stat(buf, &st) < 0) {
fprintf(2, "find: cannot stat %s\n", buf);
continue;
}
if(st.type == T_FILE) {
if(strcmp(dir.name, filename) == 0) {
printf("%s\n", buf);
}
} else if (st.type == T_DIR) {
find(buf, filename);
}
}
break;
}
close(fd);
}
int main(int argc, char *argv[]) {
if(argc != 3) {
fprintf(2, "Please enter a dir and a filename!\n");
exit(1);
} else {
char *path = argv[1];
char *filename = argv[2];
find(path, filename);
exit(0);
}
}
找的这个path有可能是一个文件,因而我们会先对其进行判断,我们会看到用到了fd = open(path, 0),这是正确的,因为在xv6中哪怕是目录也会抽象为文件,正常为其分配文件描述符,我们将在fstat(fd, &st)中处理这个描述符对应的文件来判断其状态,若为文件,则找到最后的文件名将其输出,若为目录,则循环遍历其内容,即所有的dirent结构体,这里需注意虽然目录真实的排列顺序非固定,但是前两个往往都是.和..即对应本目录和上级目录,而这次寻找显然不能遍历这两个,不然会死循环
xargs
在完成这个程序的过程中会引起对管道、重定向以及这个xargs区别的思考,首先看重定向,这是一个对应标准输入或者输出以及文件的关系,如echo hello > wc这条命令,并不是将wc视作一个指令,而是将其视作文件然后单纯地向其内容中加入hello这条文字,再对比来看管道,这在Shell中的实现意为管道的写端到读端的流入,如echo hello | wc就是将hello输入到wc的标准输入端,因而wc可以直接输出hello这一句的信息,而xargs相当于做了一个将标准输入转换为命令行参数的工作,即将hello转换为argv,而wc的内部实现实际上是将参数视作文件名而标准输入视作操作对象,所以对于echo hello | wc将直接输出hello这句话的字数等信息,而用了xargs则输出hello这个文件的内容的字数等信息
xargs应用程序实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#include "kernel/types.h"
#include "kernel/stat.h"
#inclue "kernel/param.h"
#include "user/user.h"
int main(int argc, char *argv[]) {
if(argc < 2) {
printf("Please enter more parameters!\n");
exit(1);
} else {
int bias = 0;
char *new_argv[1024];
int new_argc = argc - 1;
for(int i = 0; i < argc - 1; i++) {
new_argv[i] = malloc(strlen(argv[i + 1]) + 1);
strcpy(new_argv[i], argv[i + 1]);
}
//for(int i = 0; i < argc - 1; i++) {
//printf("%s ", new_argv[i]);
//}
char tmp[1024];
while(read(0, tmp + bias, 1)) {
if(tmp[bias] == ' ' || tmp[bias] == '\n') {
tmp[bias] = 0;
new_argv[new_argc] = malloc(strlen(tmp) + 1);
strcpy(new_argv[new_argc], tmp);
new_argc++;
bias = 0;
} else {
bias++;
}
}
new_argv[new_argc] = 0;
if(fork() == 0) {
exec(new_argv[0], new_argv);
//exec(argv[1], argv);
exit(1);
} else {
wait(0);
}
}
exit(0);
}